
生成AI・データ活用がアツい!Developers Summit 2025 セッションレポート

こんにちは、note株式会社で社内オペレーションの自動化・効率化を行っているあたまがきんに君です。
私は普段の業務では、マニュアルで行われている社内オペレーションを、ITを用いていかに筋肉質な(無駄のない)オペレーションに変えていくかに全力を注いでいます。
オペレーションの改善というと、「機能開発のような花形ではなく、裏方なのね」と思うかもしれませんが、自分の中では、自分の役割をこのように(カッコよく)表現しています。
マニュアルオペレーション(労働集約的な業務)がグロースのボトルネックにならないようにスケールさせていく(守り)
全ての業務をホワイトカラー化していき、より付加価値の高い業務に注力できるようにする(攻め)
こんな感じで表現すると、「オペレーションの改善という業務」は、あらゆる職種、あらゆる事業活動のあらゆる業務改善に至ります。そして、事業活動において守備も攻撃もやれます。
余談ですが、「労働集約型のビジネスをスケールさせていく」という観点で言うと、近しいところはコーチングプラットフォームを開発しているmentoがそうですね。ちなみに私の副業先の恵比寿のパーソナルジムもそうです。
少し逸れたので話をDevSumiへの参加経緯に戻しますと
オペレーションの改善業務の中で、最近は形式知的な業務の改善は一定やり切ってしまった(もしくは慣れてきた)んです。
そうなると次は、暗黙知の形式知化というナレッジマネジメント的な部分になってきたり、生成AIなどのテクノロジーを含めた全く新しい業務フローの構築(BPR)になってきたりすると思います。
そうなるとより深い業務理解や組織理解、データ活用や、AI活用、プロダクトマネジメントなどなどが大事になってくるわけです。
ということで、
次に負荷がかかる業務を求めて、AI活用やデータ活用や組織、プロダクトマネジメント、業務のモデリングについてトレンドをパンプアップ💪、、、間違えた。キャッチアップ👀しにきました!!
本記事では、Developers Summit 2025で学びになったセッションをピックアップして紹介していければと思います。
Day1(2/13)で勉強になったセッション
Architecture to Design:より良い設計を目指して
株式会社電通総研の米久保さんのセッションです。
より良い設計をする上では、設計の原理を理解した上で、設計原則に従うことが大事だよという話でした。
設計原則としてSOLIDを、設計原理としてCLEANが挙げられていました。CLEANの5つの原理については優先度順に挙げてくれていました。並列ではないんですねぇ。

モデリングをしていく上では、イベントストーミングという手法を用いてドメインに関する知識を引き出し整理していくのが良さそうでした。こちらの手法に関しては行ったことはなかったので使えるところで使ってみようと思いました。
良い設計に関する原理原則や、ドメインの分析手法などは、カンファレンスや書籍やウェブサイトで何度も耳にも目にもする内容ですが、何度聞いても勉強になる、非常に深みのある話だなと思いました。
「ユーザー体験」を分析するAIで変わる「世界の当たり前」
株式会社ベリサーブの瀬在さんのセッションです。
ユーザの声を把握しきれないという問題に対して、生成AIを活用したTERUSというプロダクトの紹介をしてくれました。
あらゆるところにあるレビューデータやその他フリーテキストデータのような非構造データを3つのステップに分けて構造化して可視化するというサービスです。
意見からユーザが伝えたい主張や事象を洗い出す
意味が同じ「主張」や「事象」を取りまとめ、意見をMECEにする
MECEな意見を観点別でカテゴライズし課題を洞察
さらに、ポジティブな反応とネガティブな反応かもラベリングしていたのと、それらのデータがきれいに可視化されていたので、かなり便利そうでした。
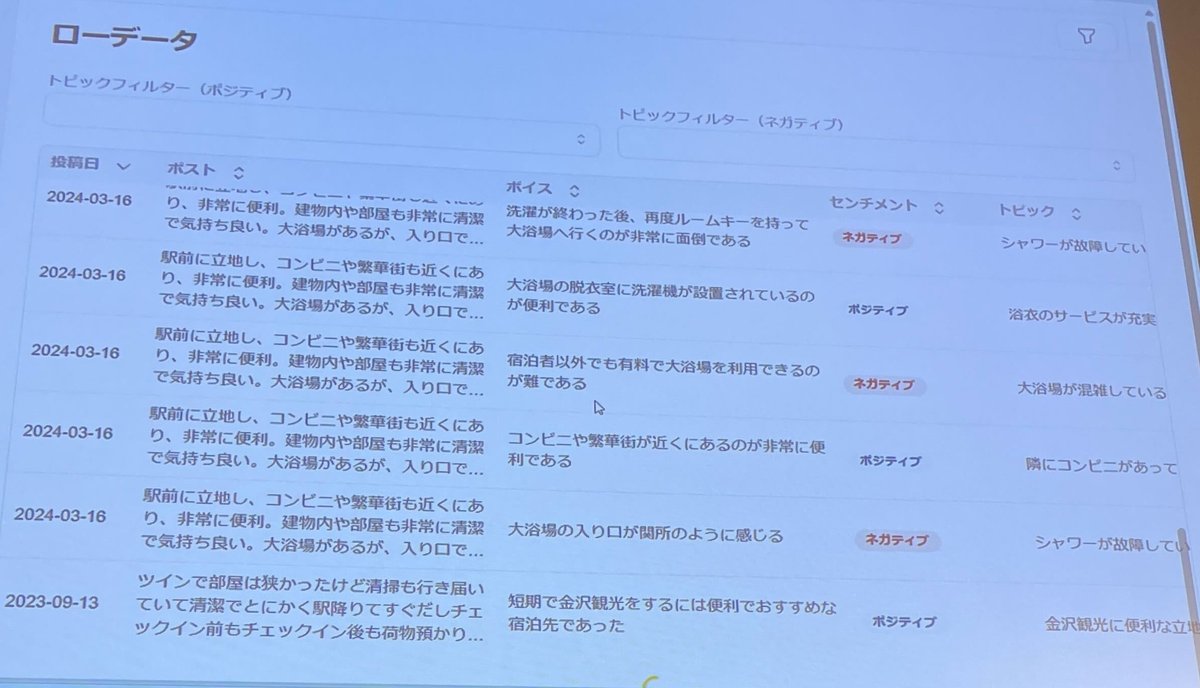
この辺りは、自分が今やろうとしていることにも近かったので具体的なイメージができてよかったと思います。
現時点で活用しきれていない非構造化データ(お問い合わせデータや顧客とのMTGの議事録データ、CRMツールにあるフリーテキストデータなど)がたくさんあるので、それらを集約して、rawデータからラベリングのような形で「意見」をMECEに抽出して、観点別(顧客規模や特定機能の利用の有無、サービス利用期間など)で見れるようにしたら、フィードバックサイクルが高速に回せるようになるだろうなと思いました。
Gemini in BigQueryが導く、データ分析の次のステップ:rawデータからインサイト獲得までのAI活用法
Google Cloud Japan合同会社の山田さんのセッションです。
日本国内で企業のデータが一年に生んだ価値が17兆円と言われているんですが、生成AIの台頭で非構造データも扱えるようになってきて、もっと価値を生み出すことができるようになるといっていました。
本セッションでは、データ活用を加速(民主化)させるためのGemini in BigQueryの機能が紹介されていました。
生成AIによるセマンティックサーチ
Data Preparationによるデータのクレンジング
自然言語でクエリ作成やクエリ解説
Dashboard Summaryによるダッシュボードの解釈や追加の分析の提案
Conversational Analyticsによる会話ベースで進めるデータ分析
Vertex AI SearchによりRAGを利用した検索と、自由なデータソース選択
私も社内でデータ活用を推進して行こうとしているんですが、データ整備だけではなく、データ活用をする人ができる限りデータアナリストのケイパビリティを獲得していかなければならないと考えていました。
その啓蒙も含めた分析体制の構築をしなければならないと思っていたので、Gemini in BigQueryのように、データ活用が民主化されていく流れなのはすごく助かるなと思いました。
そもそも教育とかせずに使えるようになる方がより良いソリューションですよね。
生成AIプロダクトを育てる技術 ~データ品質向上による継続的な価値創出の実践~
AWS Japan合同会社の久保さんのセッションです。
生成AIは、「面倒な入力の解決」と「難解な出力の解決」の2つの面で世の中に大きなインパクトを与えるが、生成AIをプロダクトに実装して運用していくとなると、いくつかのリスクについて考えなければなりません。そのリスクを減らしていくための方法として、「RAG」×「Data Centric Approach」が紹介されていました。
マクドナルドの生成AIプロダクト関するリスク発現事例だとこちら
ドライブスルーでのAI音声注文システムを2021年に導入。2023年に、注文が誤認識される様子がTikTokで拡散。100店舗以上に展開していたシステムを撤去することを2024年6月に決定。
サービスの提供停止につながったり、サービスの信頼性の低下につながるのでかなりリスクコントロールが必要だということがわかります。
4つのリスク
信憑性のリスク
悪意ある、差別的な生成のリスク
知的財産侵害のリスク
機密保持のリスク
Amazon Bedrockを使って、フリーテキストデータの構造化やタグ付けを事前にやってデータ品質を高めたり、生成AIの出力をチェックしてリスク監視をする事例が紹介されていました。
リスクコントロールの部分に関しては、出力チェックだけだと普通に手遅れになるので、生成AIの応答品質の検証環境を整えたり、トンチンカンな回答は出さないように分類問題を解くMLなどを組み合わせたり、運用していく中で不足している情報を追加していったり、Explainable AIなどを取り入れたりで解決していくのは必要かと思いました。
業務理解の深化と実践~ドメインモデリングで基幹システムを捉える
株式会社MonotaROの尾髙さんのセッションです。
モノタロウのシステムは長期運用の中で、偶有的複雑性(不要な複雑さ)が増してきており、変更容易性が失われてしまったということで、大規模なアーキテクチャの刷新を行うことになりました。
業務理解を深めるための手法としてイベントストーミングを採用していました。そして、一旦は正常系に絞って業務理解を進めていったそうです。

めっちゃ細かくイベントストーミングの進め方やアウトプットについて説明してくださったのでわかりやすかったです。
最終的にはドメインモデルに落とし込むわけですが、この規模の改修は相当大変そうでした。イベントストーミングから実装のPoC開始までに5ヶ月くらいかかったそうです。
社内のオペレーション改善を行っている自分からすると、「ドメインイベントを洗い出す際は、形式知的な部分だけではなく暗黙知的な部分にもフォーカスするとより深いドメイン理解になる」とは思っていましたが、他にもたくさんの重要な観点があることを学べてよかったです。

Day2(2/14)で勉強になったセッション
変わるモデルと変わらぬ本質 - 実践知の深掘りと次世代開発アプローチの探求
Github Japanの服部さんによるセッションです。
AIエージェント時代に、エンジニアがAIとの協働をしていく上で重要なことを話してくださいました。
明日から実践できるレベルで言うとこのあたり
適切に関心の分離を行い、クラスを分割してシンプルな設計に保つこと
作業単位をクラスレベルよりも分割すること
AIがわかりやすいように具体的で説明的な変数名をつける
スタイルガイドの明示的提供
標準化されたコード内ドキュメントを書く(RubyだとYARDかな)
オープン・クローズドの原則を意識して設計する
従来の設計で意識していたことに加えて、より意識的にAI向けにメタ情報となるようなものを埋め込んでいく必要があるんだなと思いました。
そのほかに、比較的メジャーなバージョンが技術スタックで書かれていることも重要と述べられていました。また、開発組織戦略についても触れられておりこちらも勉強になりました。
気になる方はスライド後半を参照してみてください!
インナーソースの原則
組織内コード共有のルール化
メンテナーの明確化
個人的にはコードの価値のシフトというスライドがお気に入りだったので共有します。

生成AIアプリの本番導入を可能にした3つの評価プロセス~DB設計レビュー自動化の取り組み~
KINTOテクノロジーズ株式会社の廣瀬さんのセッションです。
KINTO社のDB設計ガイドラインに則したDB設計レビューツールを自前で構築した際に、生成AIの応答品質の評価をどうやってやったのかを話していただきました。
KINTO社の取り組みでは、最初に評価の定義を行っていました。これが成功の秘訣だったようです。
生成AIの評価とは、設定した観点を数値化すること
評価観点
Quolity + Complianceをベースに真実性、安全性、公平性、堅牢性などの観点に分類。
今回のケースでは社内向けのツールなのでComplianceはスコープ外にしてQuolityを重視。
評価観点のスコア化 & スコア算出ロジック
Code-based / Human / Model-basedの3種類に大別されるが、今回はCode-basedアプローチを選択
クラウドサービスやOSSが提供するものを利用 or 自作だが、今回はレーベンシュタイン距離を採用
すごいなと思ったのが、プロンプトチューニングの仕組み評価を自動化する仕組みを構築していたことです。テスト用のデータセットを用意したら、あとはプロンプトの評価、プロンプトの修正、再評価のループを自動で回していました。
また、Amazon Bedrockはユーザ入力に対する違反ポリシーチェックや、出力に対するフィルタリングなどもできるようなので、その辺りでコンプライアンス関連のリスクは減らせそうでした。
プロンプトチューニングに関しては、LangSmithを使うとより簡単に実現できそうでした。この辺りは自分の業務でも使うことになりそうなので知れてよかったです。
生成AI時代のプロダクトの現在地点
待ちに待ったLayerXの松本勇気さんのセッションです。個人的にベストオブセッションでした。
生成AI時代ではソフトウェアの前提が変わると言われているが、アプリケーションレイヤにおいて語られることが少ないという問題提起から、生成AI時代のアプリケーション構築の新しいパラダイムについて紹介してくれていました。
新しいパラダイムを一言で言えば、AIをオンボーディングする意識です。
業務の中で戦力化するには何が足りないのか?この問いに対して必要な情報やツールの接続を埋め続けることがこれからのプロダクト開発
オンボーディングする上で必要な要素が5つ挙げられていました。
Context
LLMには記憶能力や社内情報の理解はない。どのような問題を解こうとしているのか、回答に必要な最低限の情報を揃える必要がある
Knowledge
企業の持つ知識資産や外部情報を集約・管理し、LLMの推論に活用・参照させる・LLMにとっての長期記憶的な仕組み
Workflow
LLMが業務を遂行するためのプロセス定義と実行環境。Promptだけで仕事ができるわけではない。前後のプロセスを定義することで初めて業務がこなせる。
Planning
Contextに対して、どのようにToolとKnowledgeを駆使して問題を解決するか考える。Workflowを動的に構築する仕組みとも言える。Agentのベース。Workflowはガチガチに固まったものというニュアンスで、その上に来るもの。
Evaluation
生成結果や業務遂行プロセスを検証・評価し、品質やコンプライアンスを担保する
アプリケーションのアーキテクチャやモジュール設計の話で言えば、戦力化する上で必要な上記の5つ要素の不足を埋め続けるようなモジュールを構築していくことになります。
AIをオンボーディングするということの例として、生成AIエディタのCursorを挙げていました。Cursorはソースコードのインデックスをどう作るかというところに注力しているらしく、これに関しては首がもげるほど頷きました。
全体感がわかったところで、実際に進めていく上でどこから着手すべきかとか、どこのモジュールにこだわるかなどの"要諦"をどうしようかみたいなところが次の論点になってくるのかなと思いました。
また、生成AIプロダクトを作る上で、業務理解や精度を高めるためのデータ構造や、検索アルゴリズムなどの技術的な知識の不足も見えてきたのでよかったです。
SaaSの次なる潮流BPaaS ゼロイチの事業づくりと伴走するプロダクト開発の裏側
株式会社Kubellの平本さんのセッションです。
BPaaSという新しく不確実性が高い領域に対して、具体的な方針を立てていたことが印象的でした。
Chatworkというすでにあるプロダクトをベースに、チャットのタスク発注プラットフォーム化を目指しているそうです。まるで社内の人に依頼しているように社外の人に依頼できる世界を実現したいと語っていました。
この世界の実現のためのプロダクト構想や技術戦略がとても具体的で勉強になりました。
特にプロダクト構想の中の、BPaaS窓口というのが面白かったです。BPaaS窓口を簡単に要約してお伝えすると
お客様が簡単にBPaaSを契約・発注できるシステム
サービス一覧や、案件管理や相談ができる
認証認可などの共通基盤はChatworkと連携
中小企業のお客様が多いため受発注の数が多く、そのオーバーヘッドが事業成長に影響を及ぼす可能性があるため、まずはここから効率化していく
ということでした。
最後に
note株式会社では、平日の技術カンファレンスや外部勉強会への参加は以下のシンプルな手順で、業務時間扱いで参加することができます。
チーム内(目的別および職能別のリーダー、メンバー)で共有・調整
Slackのチャンネルにて 「終日イベント参加で不在です」と連絡
私がとっても気に入っている制度の一つです。
平日にも関わらず、快く技術カンファレンスへの参加を承諾してくださったマネージャーとチームメンバー、関係者の方々ありがとうございました。
DevSumi参加の目的だった、以下のトピックについては期待値以上の学びがありました。
データ活用周り
業務内容の深掘り
生成AI活用周り
おかげでアクションや仮説の解像度が高まったと思います。これを会社に還元していけるように引き続き頑張ります。
いいなと思ったら応援しよう!
